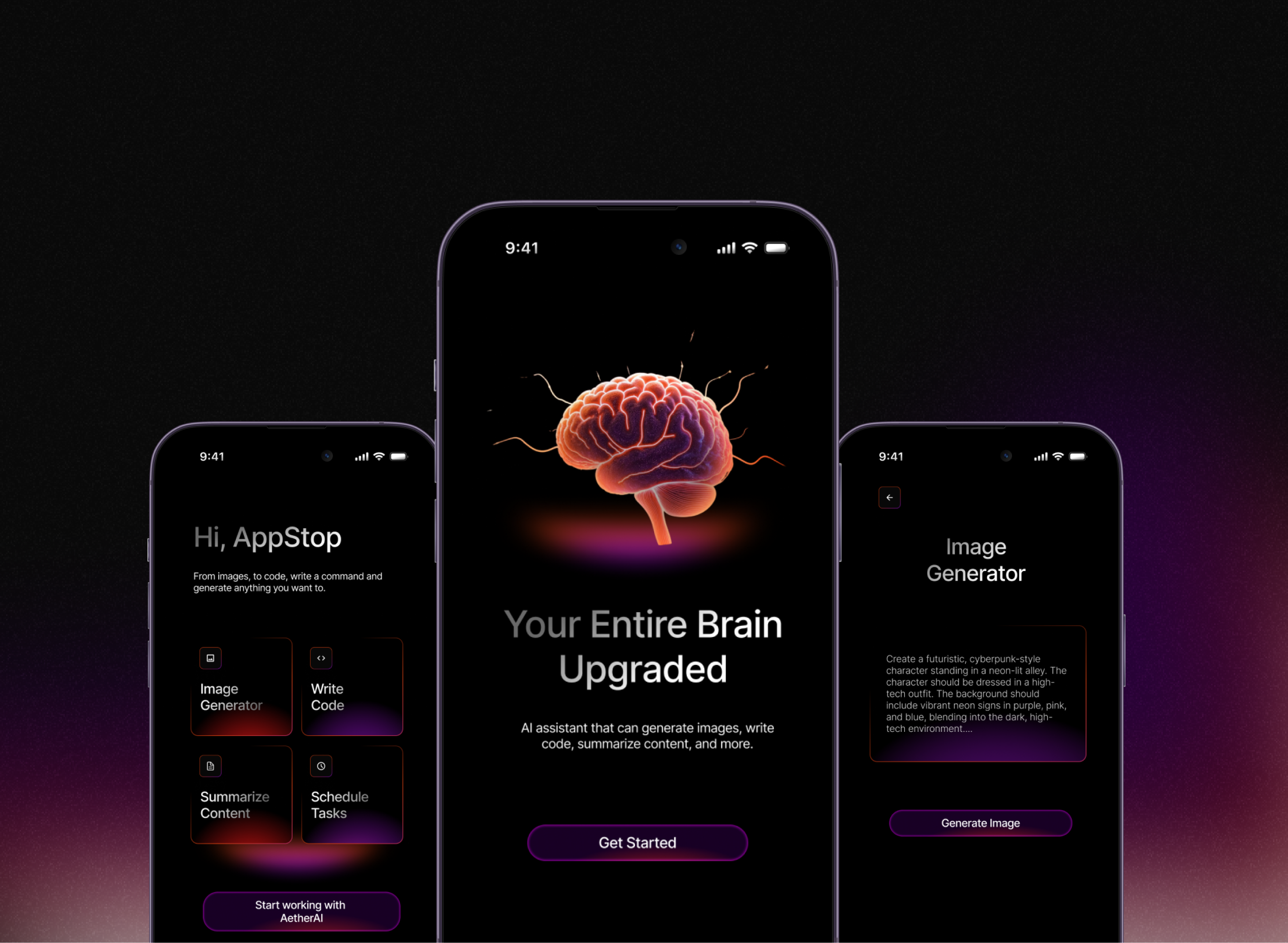
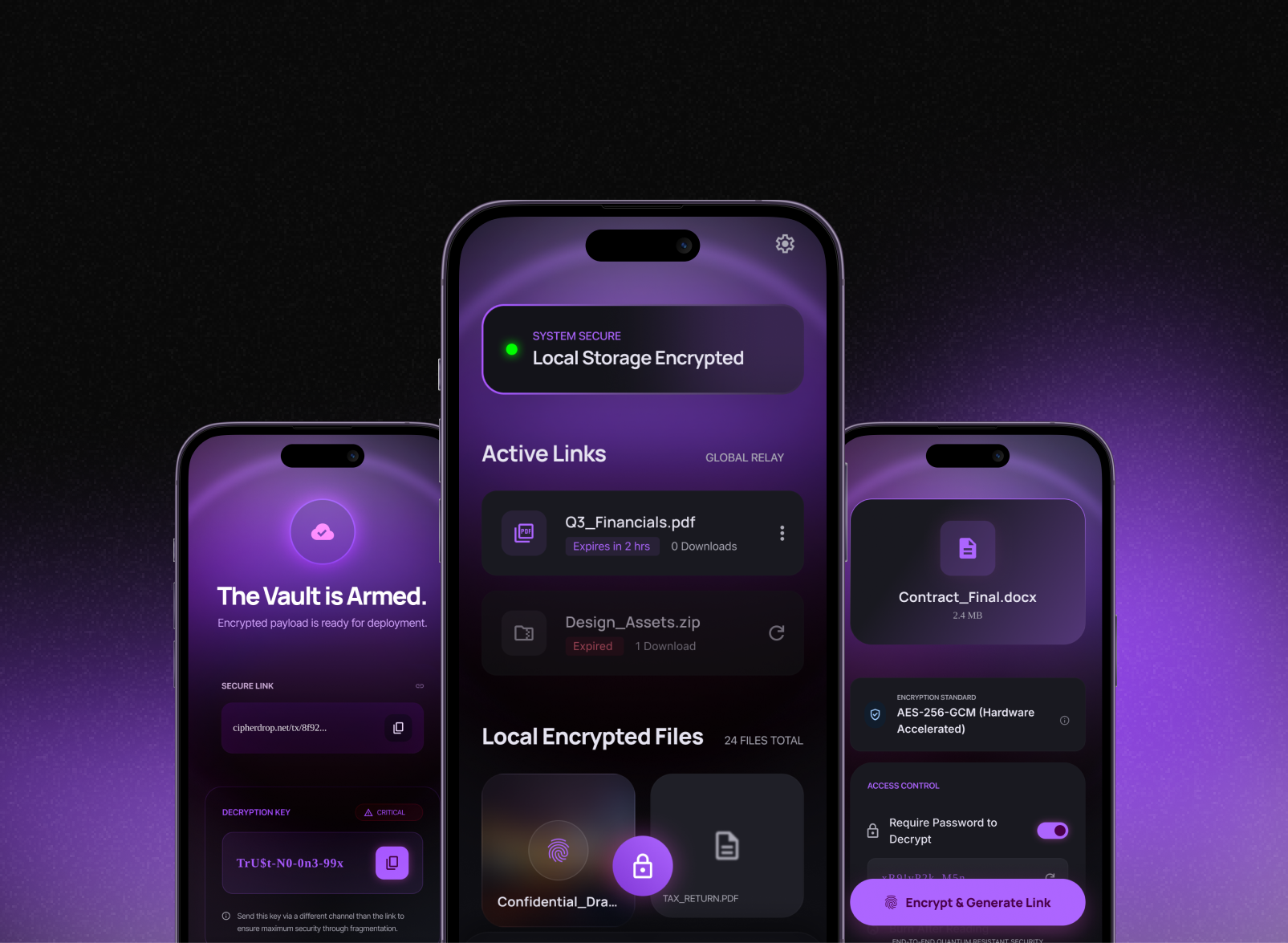
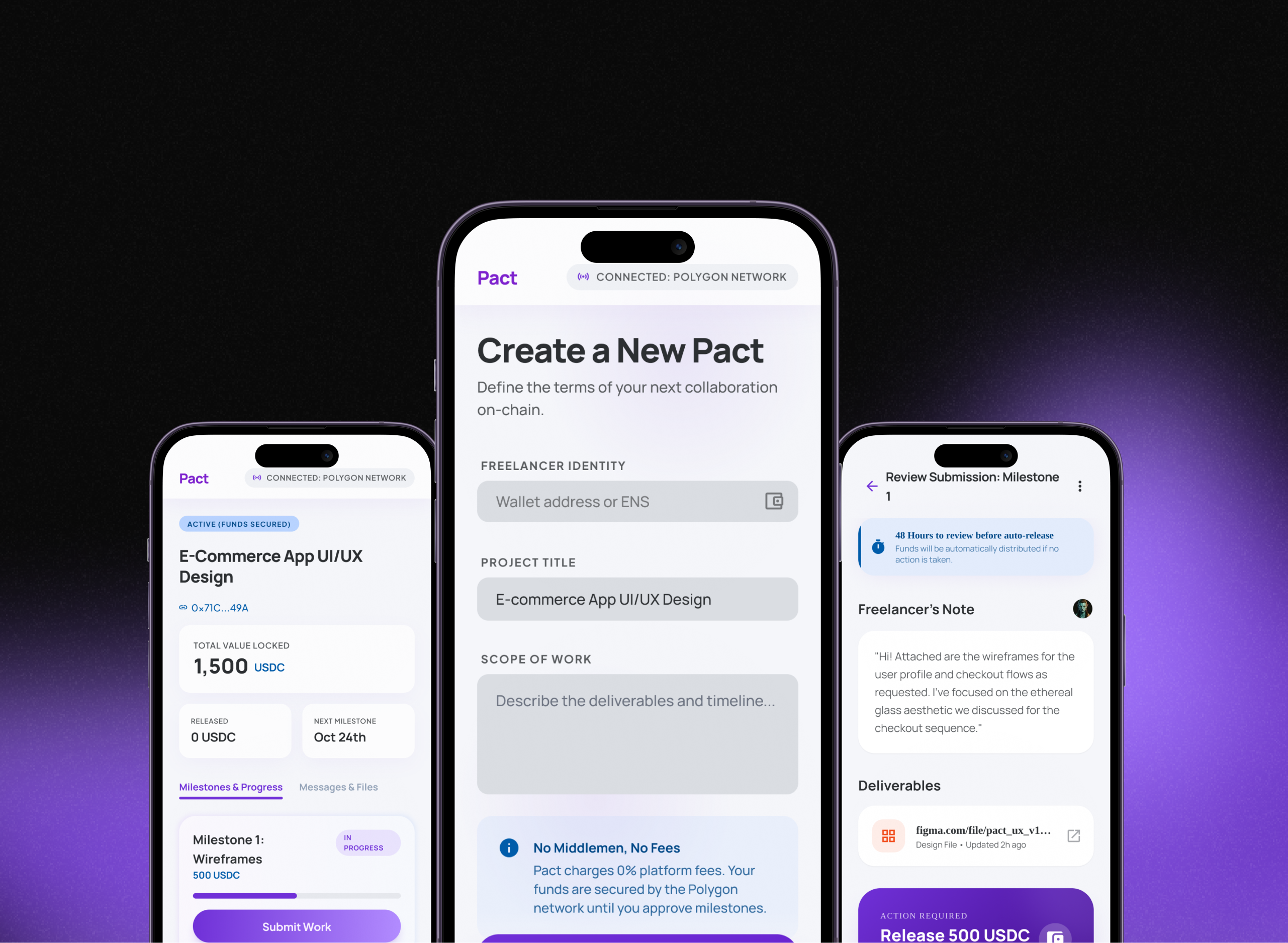
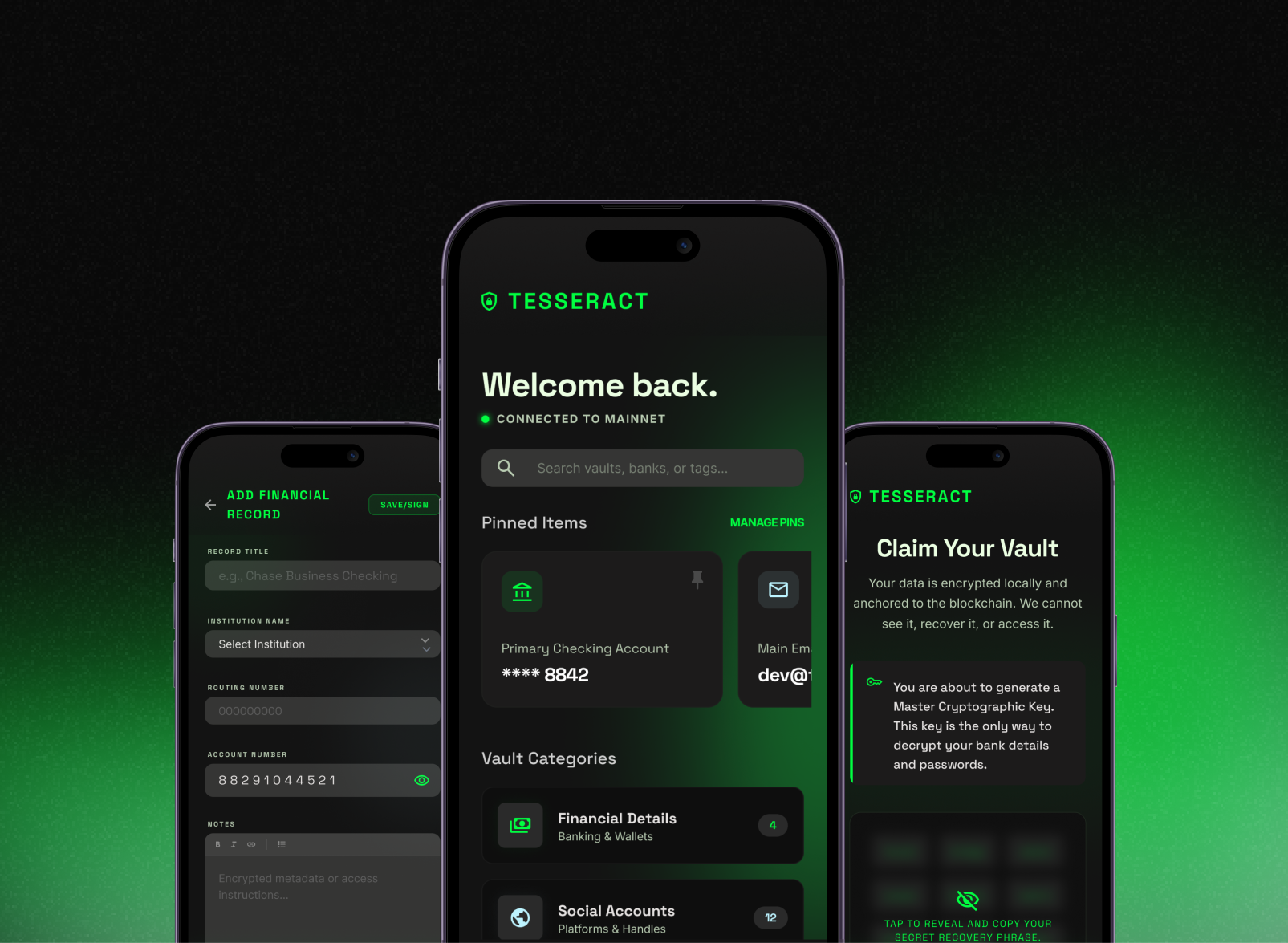
Multi-model LLM orchestration layer built in mobile — routes prompts to the right model based on task type, maintains conversation context via a vector memory store, and streams responses token-by-token for a responsive feel even on long completions.
LangChainOpenAI APIPineconeRAGStreaming
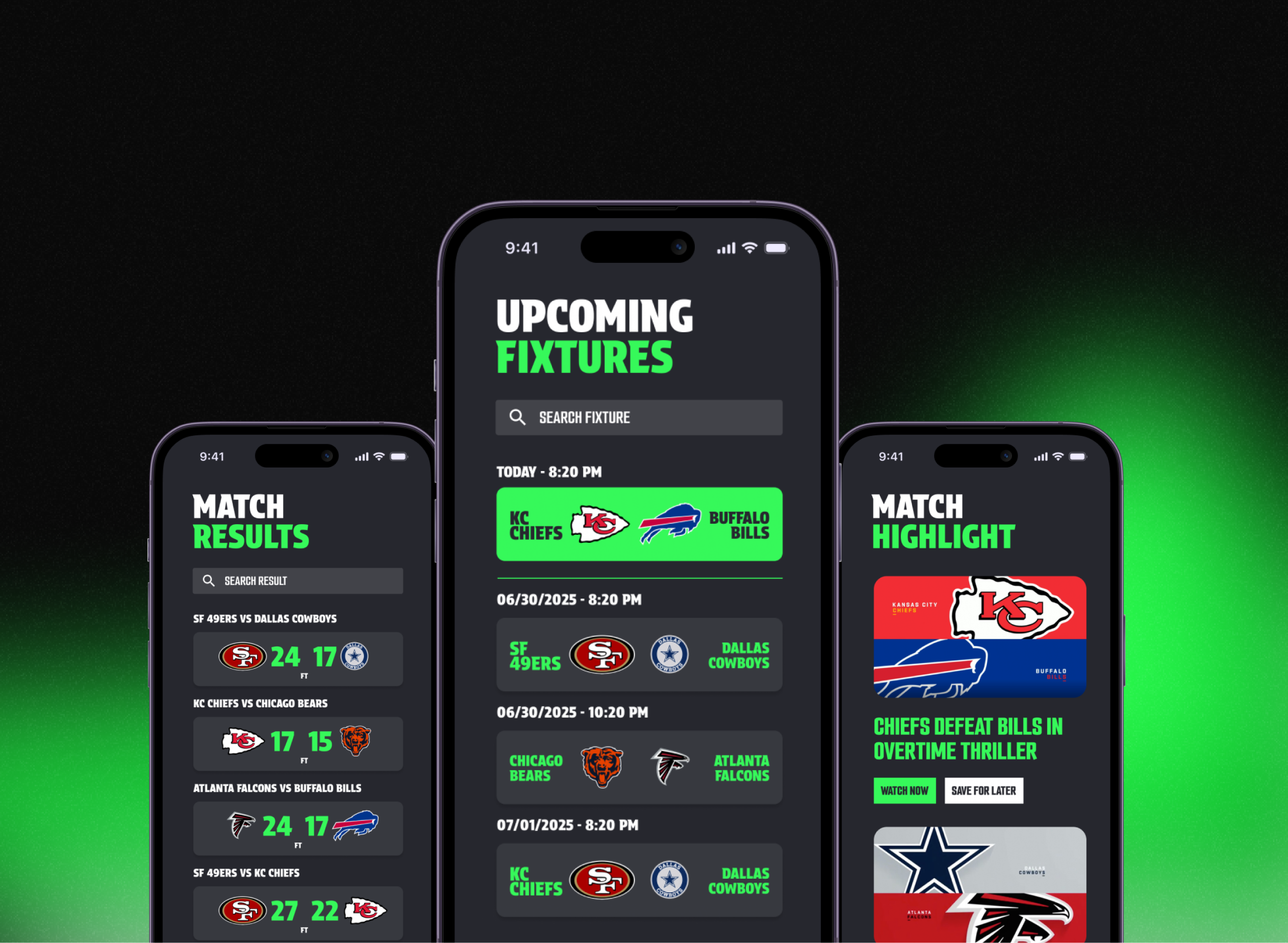
NFLLine
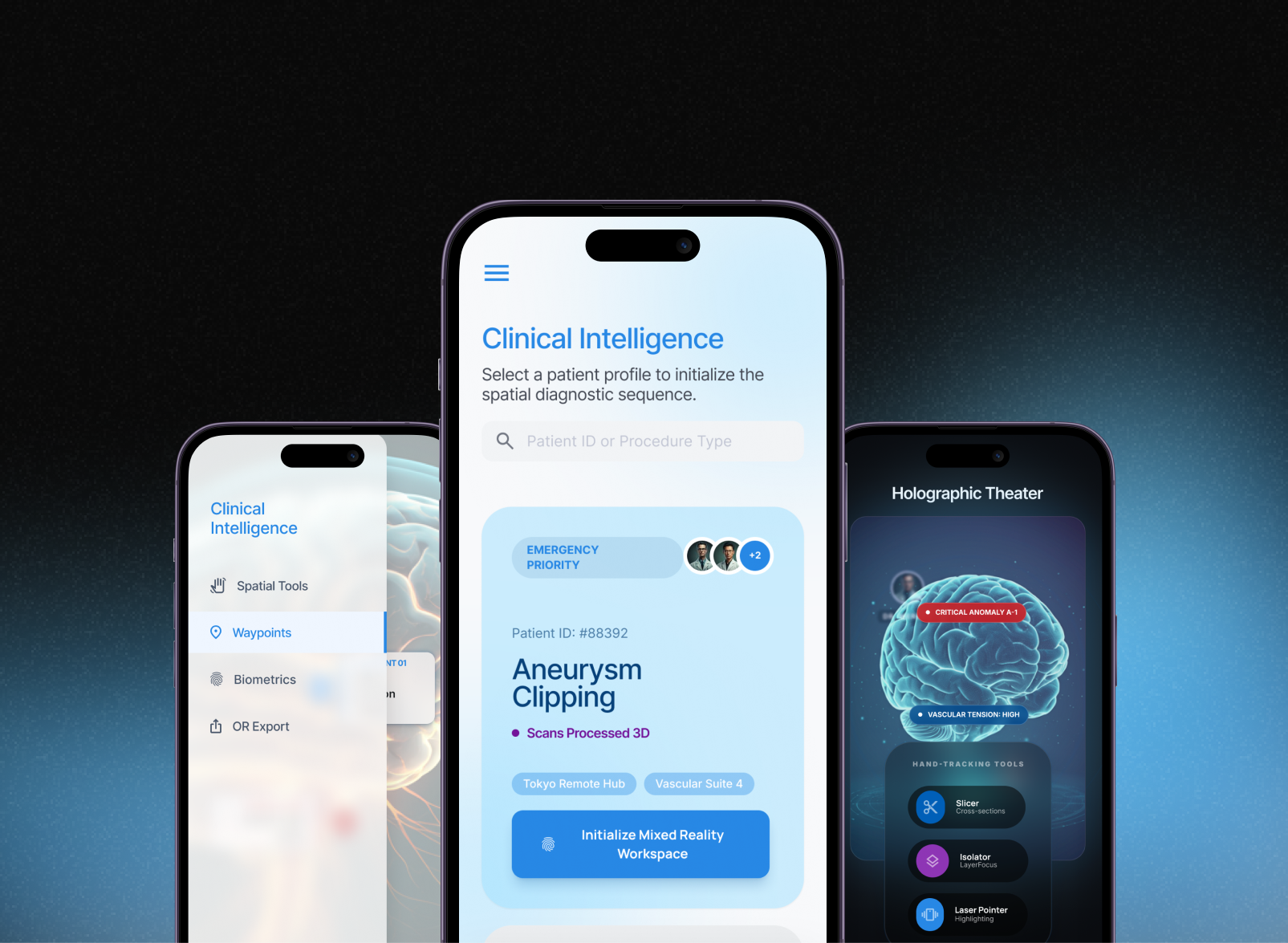
Real-time ML inference pipeline that processes live game events to update win probabilities, injury impact scores, and performance ratings as play unfolds — with a collaborative filtering model that personalises which insights surface first based on each user's team and player interests.
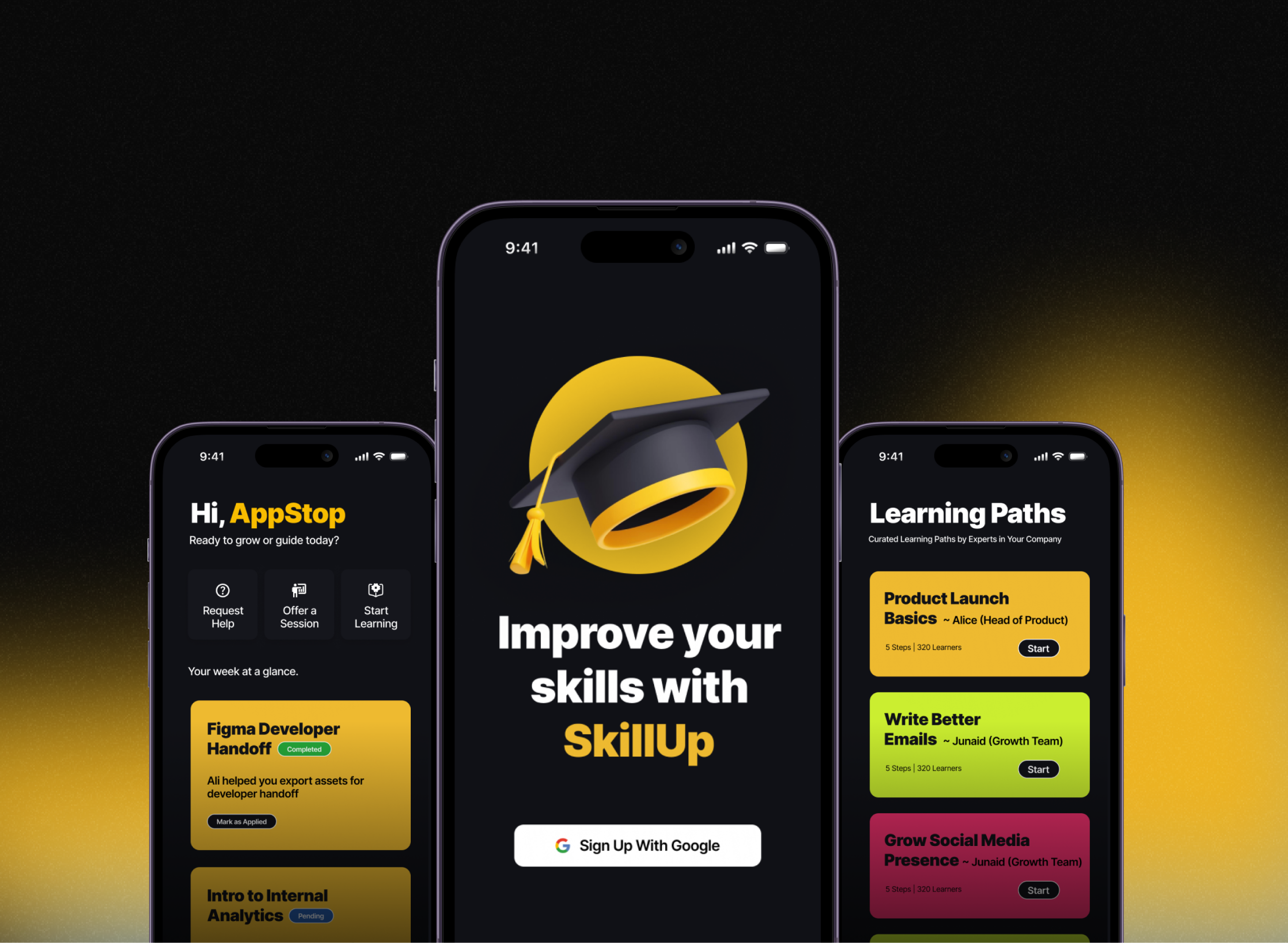
Adaptive curriculum engine built on a knowledge graph — models each learner's mastery state per concept, uses spaced repetition scheduling to surface review at the optimal retention window, and re-routes the learning path in real time when a gap is detected. Average module completion 3× industry benchmark.
PythonGCP Vertex AIKnowledge GraphSpaced RepetitionReal-time ML
Why Choose Us?
Most AI features fail in production. The model was fine — the integration wasn't.
We pick the model that fits, not the one that's trending
GPT-4o is not the right answer to every AI problem — and recommending it regardless of the use case is a red flag, not a credential. We assess whether your product needs an LLM, a classification model, a recommendation system, or a lightweight on-device model, and we recommend the approach that's fastest, cheapest, and most accurate for your specific data and users.
On-device first, cloud where it makes sense
On-device inference means lower latency, no API costs, and AI that works offline. We use Core ML and TensorFlow Lite to run models locally wherever the use case allows — reserving cloud inference for tasks that genuinely need it. Your users get faster responses; you get lower operating costs.
Evals and monitoring built in from sprint one
AI features that aren't measured degrade silently. We build evaluation pipelines, accuracy thresholds, and cost monitoring into the architecture from the start — so you know when the model is drifting, when API costs spike, and when a retrain is due, before your users notice.
Expected Outcomes
01
AI features that survive contact with real users
Production AI fails for reasons that have nothing to do with model accuracy — cold start latency, edge-case inputs, connectivity gaps, and prompt injection. We test for these from day one, not after the first 1-star review mentions "the AI is broken."
02
Running costs you budgeted for, not discovered after launch
LLM API costs scale with usage in ways that surprise founders at exactly the wrong moment — right after a successful launch. We model inference costs, build in caching, batching, and model-routing logic, and give you a cost projection before a single API call goes to production.
03
A model that improves with your product, not despite it
We design feedback loops, fine-tuning pipelines, and retraining schedules into the architecture — so the model gets better as your data grows, rather than becoming stale six months after launch when user behaviour has shifted.
04
AI your users trust enough to rely on
Explainability, graceful fallbacks, and clear confidence signals — users abandon AI features the first time they feel misled. We build the trust layer into the UX: showing uncertainty when it exists, defaulting gracefully when the model is out of its depth, and never pretending confidence the model doesn't have.
But, Why App Stop?
We Build What Your Audience Needs
App Stop takes ownership of both product thinking and execution. We combine design clarity, engineering discipline, and market context to ship experiences that are fast, usable, and ready to scale.
We define the product problem, success metrics, and the delivery track that fits the business.
02
Architect
We shape the technical foundation, delivery milestones, and risk controls before sprint work begins.
03
Build
We execute in focused iterations with demos, QA, instrumentation, and release planning in parallel.
04
Harden
We launch with observability, support, and a practical roadmap for what comes next.
Selected Work
Featured Mobile Apps
FAQ
Frequently Asked Questions
Do you only work with large language models?+
No — and recommending one regardless of the problem is a red flag. We work across LLMs, computer vision, recommendation systems, classification models, on-device inference, and predictive analytics. The right tool depends on your data, your latency requirements, your budget, and what your users are actually trying to do. We'll tell you which approach fits before any build starts.
Can you add AI features to an existing app?+
Yes — and it's one of our most common engagements. We assess the existing architecture first to understand what integration points are available, what data is already being collected, and where AI can add genuine value rather than just novelty. Features get integrated through APIs, background inference services, or on-device models depending on what the app's current structure supports. We won't recommend a full rebuild to add AI unless the codebase genuinely can't support the integration cleanly.
How do you manage AI cost and accuracy?+
Cost and accuracy are the two things that kill AI features in production and both need to be designed for, not monitored after the fact. On cost: we build in caching for repeated queries, model routing (cheaper model for simple tasks, expensive model only when needed), and usage dashboards with budget alerts. On accuracy: we define evaluation metrics before build starts, run automated eval suites on every model change, and set accuracy thresholds that trigger a review before a degraded model reaches users.
How do you handle AI data privacy for regulated industries?+
Data sent to a third-party LLM API is data leaving your infrastructure — and for health, financial, or personally identifiable data, that has regulatory implications. We address this by defaulting to on-device inference wherever possible, using data anonymisation before any cloud API call, and implementing RAG architectures that retrieve context from your own infrastructure rather than embedding sensitive data into prompts. If your use case requires stricter controls, we can build with self-hosted models that never send data to a third party.
What happens when the AI gives a wrong or harmful answer?+
Every AI system produces wrong outputs — the question is whether the product is designed to handle it gracefully. We build output validation, confidence thresholds, and fallback states into every AI feature. Where the stakes are high (medical, financial, legal adjacent), we implement human-in-the-loop checkpoints and explicit uncertainty signals so users are never presented with a confident wrong answer. Guardrails, prompt hardening, and output filtering are part of the standard build — not an optional extra.
Claim a $799 Consultation, on Us!
Let's build an app Your Users Will Love
Expect a response from us within 24 hours
We're happy to sign an NDA upon request.
Get access to a team of dedicated product specialists.